Face Recognition
Overview
A facial recognition system is a computer application for automatically identifying or verifying a person from a digital image or a video frame from a video source. One of the ways to do this is by comparing selected facial features from the image and a facial database. It is typically used in security systems and can be compared to other biometrics such as fingerprint or eye iris recognition systems. (wikipedia)
Goal of the Research
Contribute to the improvement of the facial recognition system, focusing mainly on increasing its accuracy performance.
Two types of the Face Recognition
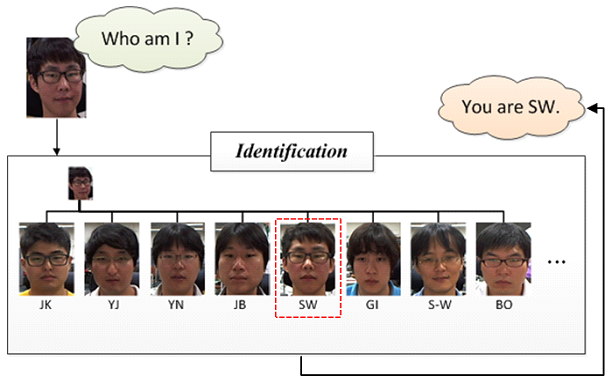
- Face identificationFace identification answers the question, "Who am I?". An input image called a probe image is given to the system, and the system classifies the image among interested subjects called the gallery set. So the answer will be the most similar one's name, for example "You are SW" using a trained classifier.
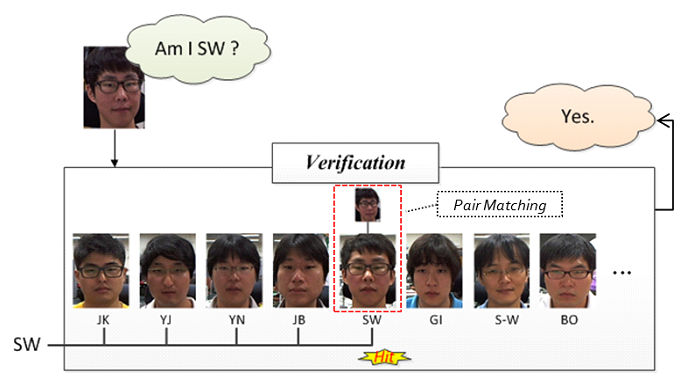
- Face verificationFace verification is based on pair matching, so the answer will be just "Yes" or "No". An input image with specific name is given to the system, and the system performs pair matching between the probe image and the gallery image which belongs to the given name.
Why so challenging?
 |
These pictures are from a well-known face database, "Labeled Faces in the Wild". This database provides benchmarking tests based on pair matching to compare performances between algorithms. And the pictures are collected from news, so each face image is taken under unconstrained conditions. Unconstrained conditions involve large variations caused by pose, lighting condition, facial expression, occlusion, age, blur, image quality and so on. As you can see, images from the same person may look quite different and that is the main reason of the difficulty.
|
Current position of the Face Recognition
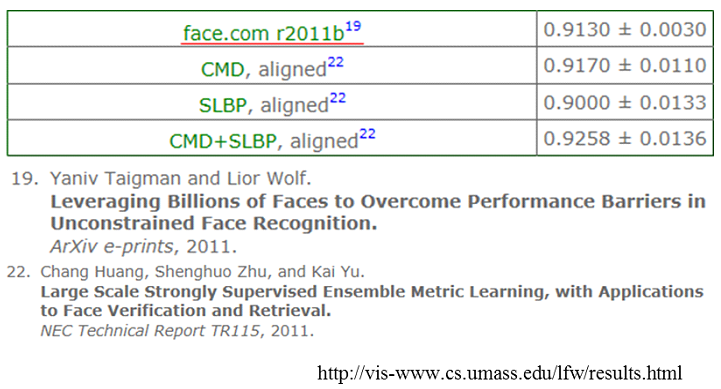 |
This table represents results of commercial and current best performing systems on LFW benchmarks (face verification perforamance). Here, ‘face.com’ is one of the most successful companies about face recognition. They have supplied web-based API for face recognition through internet until recently, and have been acquired by Facebook on June 2012. As you can see, the world-best performance is a little more than 90% in case of the unconstrained face verification. The performances are closing to human accuracy where humans achieve around 97%. Then, how about in case of unconstrained face identification?
|
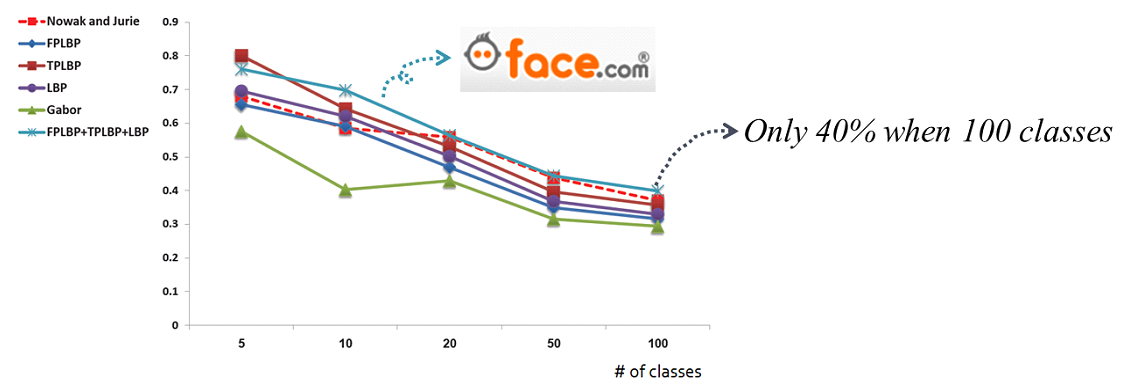
This graph is answering the question. In the paper of ‘face.com’, they compared their method with others under unconstrained face identification using LFW dataset. The recognition rate is started from 80% at 5 classes and decreases by up to 40% at 100 classes. This result clearly shows the current limitation of face recognition.
| |
General flow of the Face Recognition
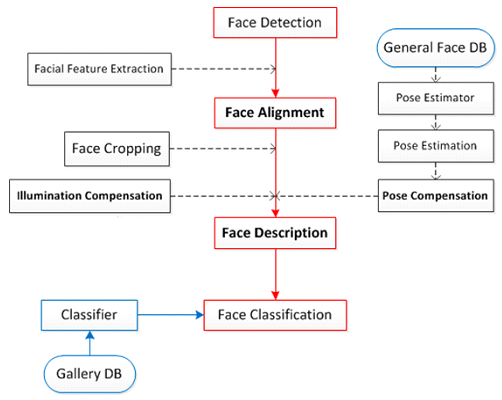 |
This flow diagram is about general steps of unconstrained face identification. From detected face region, face is aligned using general alignment method or piece wise affine warping with facial feature points from facial feature extractor. Before face description step, cropping face into components can maximize benefits from localization. And also, some compensation like illumination and pose compensation may be needed to reduce variations caused by unconstrained conditions. And then face is represented into vector or matrix using face descriptor. At that step, codebook or dimensional reduction scheme may be used as necessary. Finally, the represented face is passed through trained classifier to get final result. The following figure shows the demonstration of the flows.
|
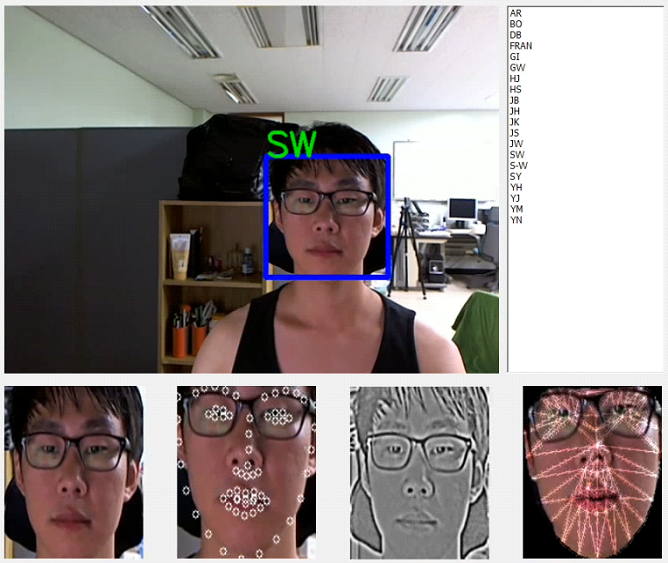
We hope to realize ‘Face Auto Tagging System’ in the near future.
If interested, do not hesitate to contact us. It will be great chance to you.
If interested, do not hesitate to contact us. It will be great chance to you.

Contents of the Research
- Face detection
- Facial feature extraction
- Facial pose estimation
- Face alignment
- Face description
- Illumination compensation
Required Knowledge for the Research
- Probability and Statistics
- Linear Algebra
- Machine Learning
- Pattern Recognition
- Image Processing